Multi-Scale image segmentation
Disclaimer
I tried to reproduce the results from Hierarchical Multi-Scale Attention for Semantic Segmentation
(paper link). I had no contribution over the original paper, all I did was to recreate the same results from the paper.
Image segmentation is a method for categorizing each pixel in a frame. Object detection is one of the many applications that image segmentation has. Instead of processing the entire image, a common practice is first to use image segmentation to find an approximate of the object's region. Then, the object detector can operate on a bounding box already defined by the segmentation algorithm. This prevents the detector from processing the entire image, improving accuracy and reducing inference time. There are many different segmentation models out there, all with unique capabilities and constraints. The Andrew Tao paper introduced a model that uses different scales of images as input while using output information to make a more accurate segmentation mask.
One of
Andrew Tao et. al main contributions were where for each scale, a dense mash was learned,
and they combined the multi-scale predictions in a pixel-wise manner, followed by pixel-wise summation between different scales to get the final output. They also refer to
Chen’s method as explicit. They used their hierarchical method to learn a relative attention mask between adjacent scales instead of learning attention masks for each fixed scale set. During training, they only trained them with the adjacent scale pair. This allows the network network learns to predict relative attention for a range of image scales
Figure 1 belonging to the
original paper, shows the architect of the entire model.
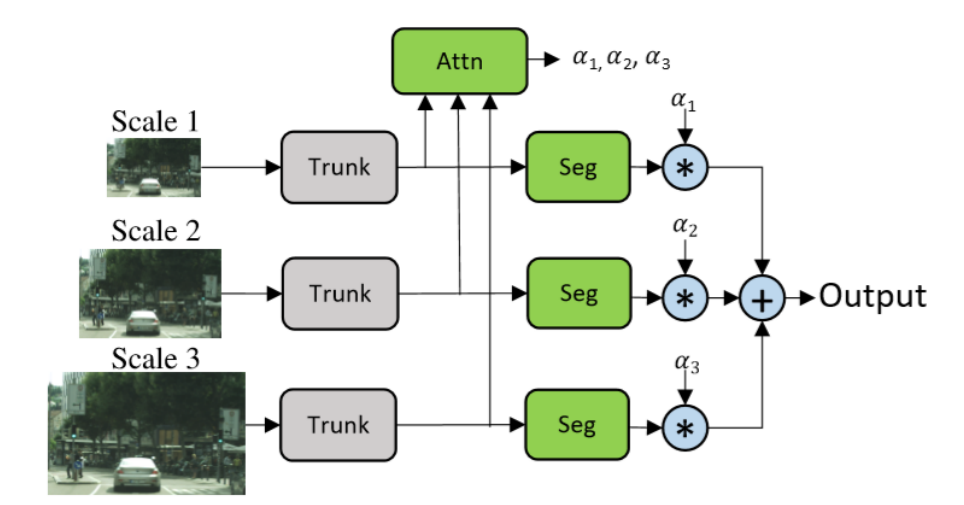
Figure 1: Image from original paper
- Trunk: One of the key parts in the architect of the model was the structure of the trunk. There were
several network models for this part of the network, we used ResNet50, ResNet101, and MobileNet for this part on the network.
- Segmentation: One of the other key parts of the network was the segmentation part of the model, wherein the following paper hasn't clearly mentioned what kind of segmentation model they have used, so we tried DeepLab V3 and DeepLeab V3 + for the segmentation part, in the following we are going to give some information about this two networks.
- Backbone: ResNet-50
- Semantic Head: (3𝑥3 𝑐𝑜𝑛𝑣) → (𝐵𝑁) → (𝑅𝑒𝐿𝑈) → (3𝑥3 𝑐𝑜𝑛𝑣) → (𝐵𝑁) → (𝑅𝑒𝐿𝑈) →
(1𝑥1𝑐𝑜𝑛𝑣)
- Attention Head
- Auxiliary semantic head: (1𝑥1 𝑐𝑜𝑛𝑣) → (𝐵𝑁) → (𝑅𝑒𝐿𝑈) → (1𝑥1 𝑐𝑜𝑛𝑣)
The dataset that we were using in the following project was the
Cityscapes dataset, which was
labeled for semantic understanding. But we did not need the entire dataset since image segmentation was our only objective.
Figure 2 shows a sample ground image and it's segment map.

Figure 2
| Group |
Classes |
| Flat |
road, sidewalk,parking,rail track
|
| Human |
person, rider |
| Vehicle |
car, truck,bus, on rails, motor cycle |
| Construction |
building, wall,fense, guard rail, caravan, bridge |
| Object |
pole, pole group, traffic sign, traffic light |
| Nature |
vegetation, terrain |
| Sky |
sky |
| void |
ground, dynamic, static |
Table 1
In the beginning, our ultimate goal was to build up two-stage and three-stage hierarchical multi-scale attention by trying both Resnet-50 and HRNet-OCD as the trunk and the DeepLab v3+ as the segmentation block. However, this was not possible due to our computational limitations (especially the small GPU memory). Inevitably, we replaced the HRNet-OCD architecture with MobileNet in our experience due to its smaller size and fewer parameters. Even after this, we were still unable to train our models end to end; instead, we relied on transfer learning methods to obtain acceptable results. Our main approach in training the hierarchical models was to train different 3 segmentation models for segmenting images with three scales (2, 1, and 0.5) and eventually use the trained trunk and segmentation blocks for the original models. We use the same architecture as the hierarchical models' initial stage for training trunks and segmentation blocks on images with various sizes.
Since the entire was huge, we weren't able to train this model in an end-to-end manner. Instead, we trained each part separately and combined them in the end.
Figure 3 shows an example of the network we trained. The top image represents the original image. The middle represents the ground truth segmentation. The bottom image represents the predicted segmentation from our model.
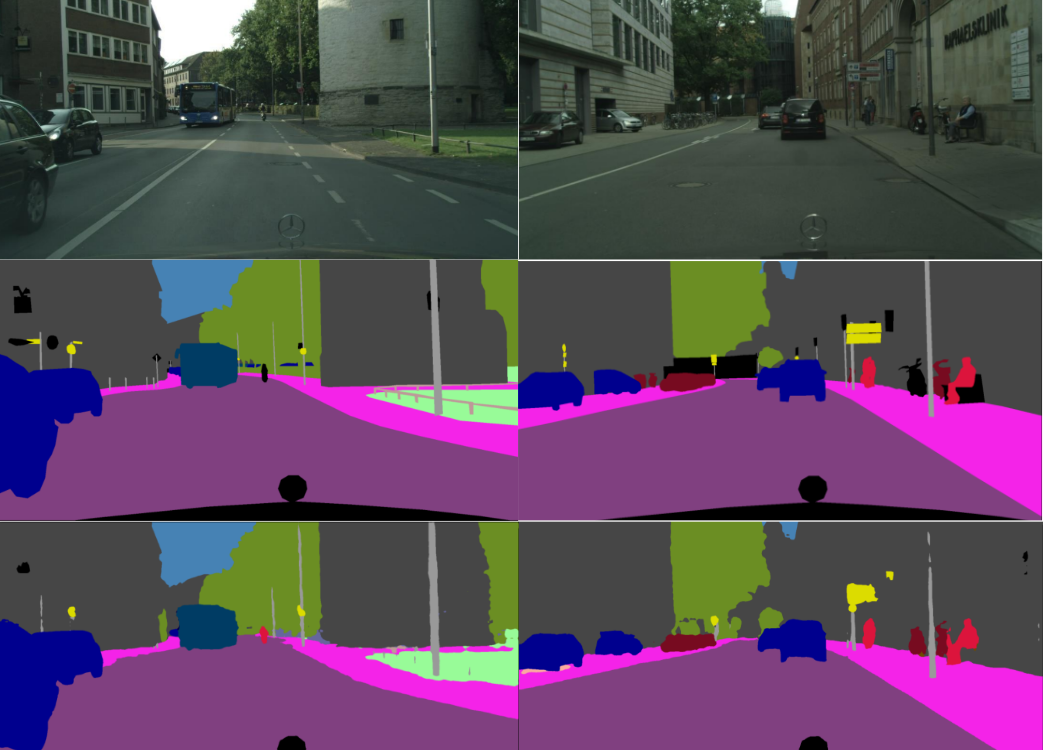
Figure 3
Table 2 shows the result for different architectures.
| Trunk |
Segmentation Block |
Image Scale |
#Epochs |
Mean IOU |
Average Accuracy |
| MobileNet |
DeepLab V3+ |
0.5 |
7 |
51.4% |
71.3% |
| MobileNet |
DeepLab V3+ |
1 |
7 |
50.6% |
68.7% |
| MobileNet |
DeepLab V3+ |
2 |
5 |
50.3% |
68.2% |
| ResNet |
DeepLab V3+ |
0.5 |
6 |
50.1% |
68.4% |
| ResNet |
DeepLab V3+ |
1 |
6 |
48.0% |
76.3% |
| ResNet |
DeepLab V3+ |
2 |
5 |
49.0% |
68.1% |
Table 2
