Human joint Pose Estimator
Disclaimer
I tried to reproduce the results from DeepPose: Human Pose Estimation via Deep Neural Networks (project link). I had no contribution over the original paper, all I did was to recreate the same results from the paper.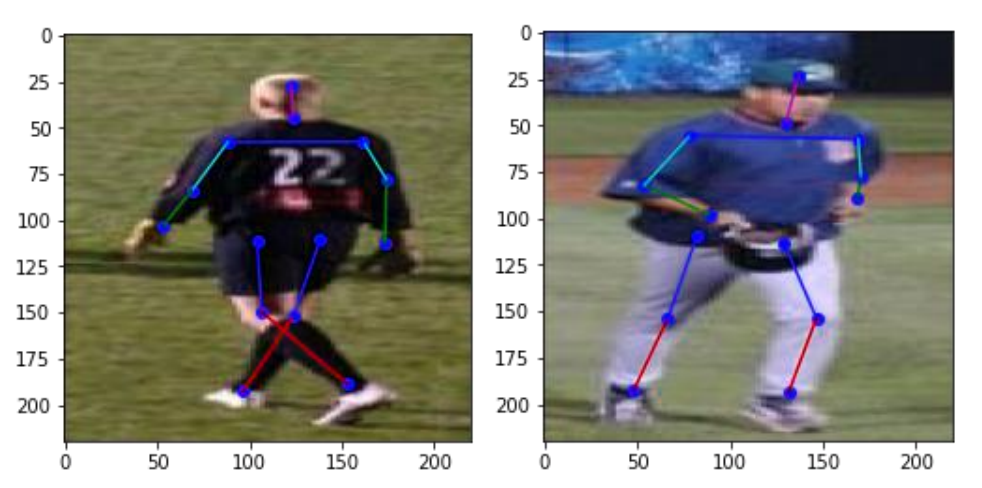
1. Introduction
The problem of human pose estimation, which involves locating human joints in images, has been extensively studied in the computer vision community. This problem is challenging due to factors such as strong articulations, occlusions, and the need to capture context. Most work in this field has focused on modeling articulations using part-based models, which have limited expressiveness and only model a small subset of interactions between body parts. Holistic methods have been proposed, but have had limited success in real-world problems. In this paper, the authors propose a novel approach to human pose estimation using deep neural networks (DNNs). They show that DNNs can effectively capture the full context of each body joint and present a simple yet powerful formulation of the problem as a joint regression task. They propose a cascade of DNN-based pose predictors to refine joint predictions and achieve state-of-the-art results on four widely used benchmarks. The approach is shown to perform well on images with strong variation in appearance and articulations, and generalizes well across datasets..
2. Architecture
2.1 Pose Vector
- The authors of this paper have devised a technique to depict the human body in the form of pose. This is achieved by encoding the location of all `k` body parts into joints which are collectively known as a pose vector. The definition of this pose vector is outlined in the paper.
- In this context, the notation `y_i` refers to the `x` and `y` coordinates representing the location of the ith body joint.
- The representation of the image in this paper is structured as a tuple `(x, y)`, where x is the image data and `y` represents the ground truth pose vector data.
- The described coordinates are absolute image coordinates on the full image size, which can cause issues if the image is resized. To avoid this, the coordinates are normalized with respect to a bounding box that encloses the human body or parts of it. These bounding boxes are represented by `b = (b_c, b_h, b_w)`, where `b_c` is the center of the bounding box and `b_h` and `b_w` are the height and width of the bounding box, respectively.
- We normalized the location coordinates using following formula.
- Finally we get the normalized Pose vector coordinates.
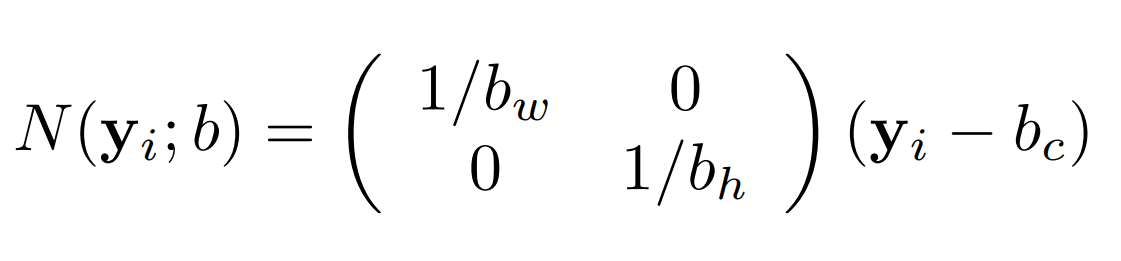
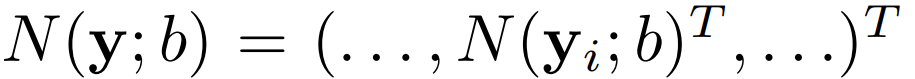
2.2 CNN Architecture
- The authors of this paper uses AlexNet as their CNN architecture because it had shown great results on Image Localization task.
- The location coordinates were normalized using the following formula, where `theta` denotes trainable parameters (weights and biases) and `psi` denotes the neural architecture applied to normalized pose vector `N(x)`. The predicted output `y*` can be obtained by denormalizing the output `(N-1)`.
- This neural network architecture takes image of size 220×220 and apply an stride of 4.
- The CNN architecture contains 7 layers which can be listed as : C(55×55×96) — LRN — P — C(27×27×256) — LRN — P — C(13×13×384) — C(13×13×384) — C(13×13×256) — P — F(4096) — F(4096)
- Where `C` is convolution layer which uses ReLU as activation function to introduce non-linearity in the model, LRN is local response normalization, `P` is pooling layer, and `F` is fully connected layer.
- The last layer of architecture outputs `2k` joint coordinates.
- The architecture uses `L2` loss function to minimize the distance between predicted coordinates and ground truth loss function.
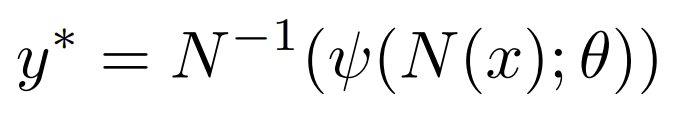
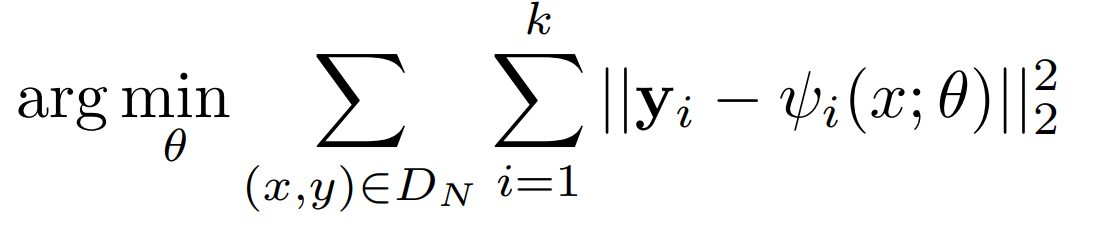
2.3 DNN regressor:

- It is not easy to increase the input size to have a finer pose estimation since this will increase the already large number of parameters. Thus, a cascade of pose regressors are proposed to refine the pose estimation.
- Now, we represent the first stage with following equation
- Where `b^0` represents full image or bounding box obtained by a person detector.
- where diam(y) is the distance of opposing joints, such as left shoulder and right hips, and then scaled by `sigma` to make it `sigma` `diam(y)`.
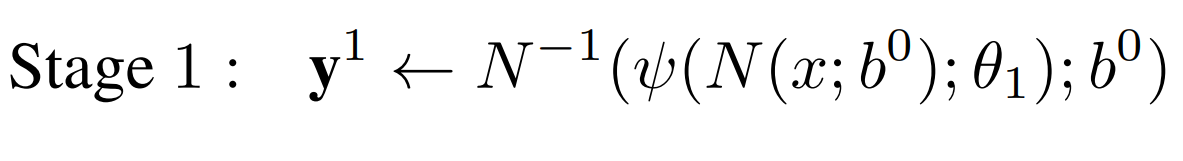
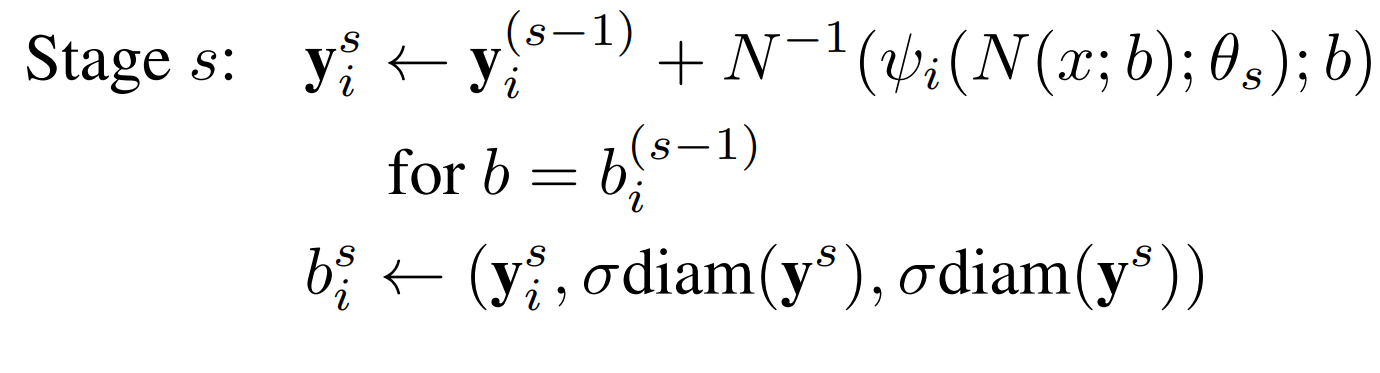
3. Accuracy Metrics
3.1 Percentage of Correct Parts (PCP)
The Percentage of Correct Parts (PCP) is a metric used to measure the detection rate of limbs. It considers a limb to be detected if the distance between the two predicted joint locations and the true limb joint locations is no more than half of the limb length. However, the PCP metric has limitations in that it penalizes shorter and more difficult to detect limbs.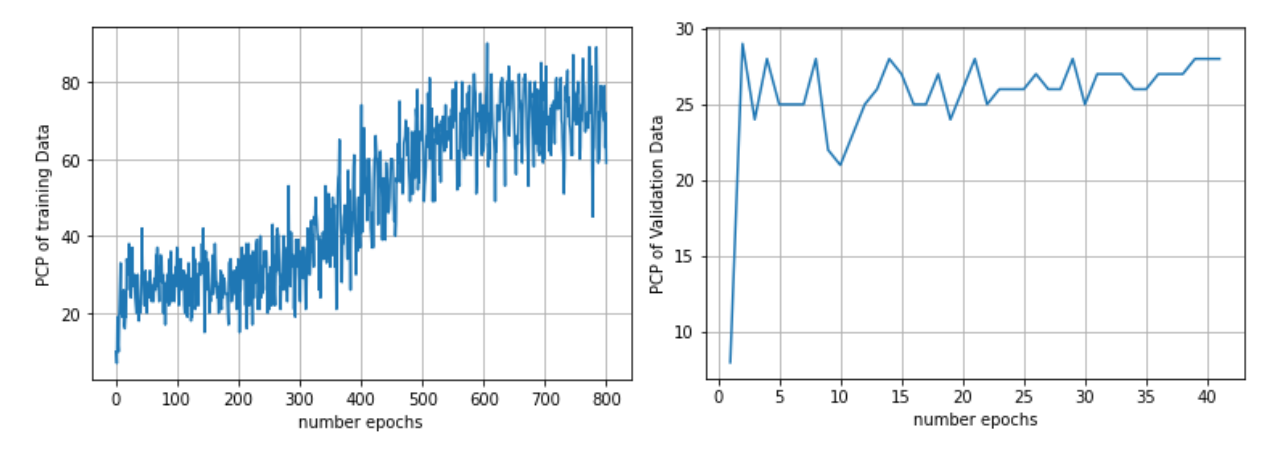
3.2 Percent of Detected Joints (PDJ)
Another metric called the Percent of Detected Joints (PDJ) has been proposed to address the limitations of the PCP metric. This metric measures joint detection rates by considering a joint to be detected if the distance between the predicted and true joint locations is within a certain fraction of the torso diameter. By adjusting this fraction, detection rates can be obtained for different levels of localization precision.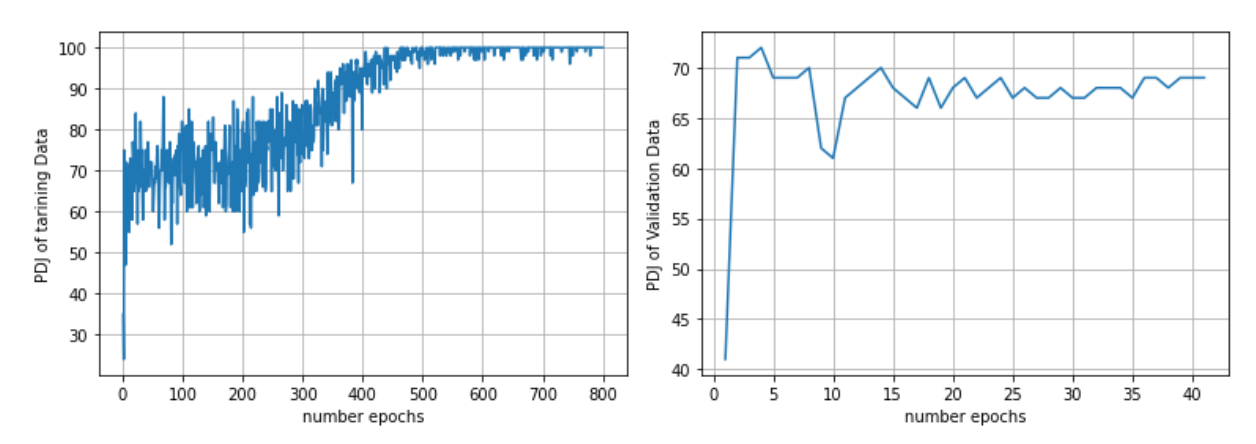
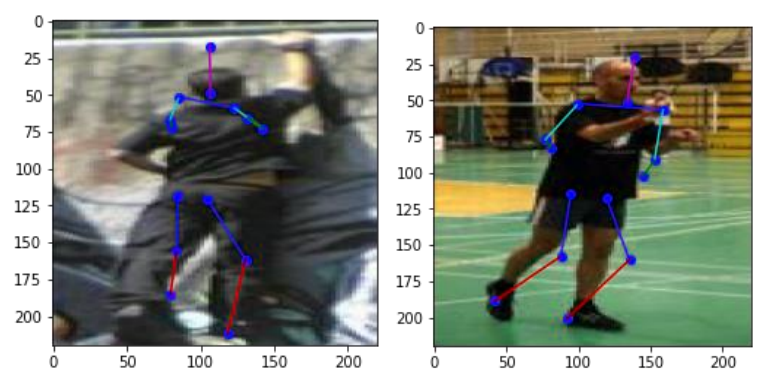
4. Results
After we trained the model, we tested it over the training and testing dataset to see its performace.4.1 Train images
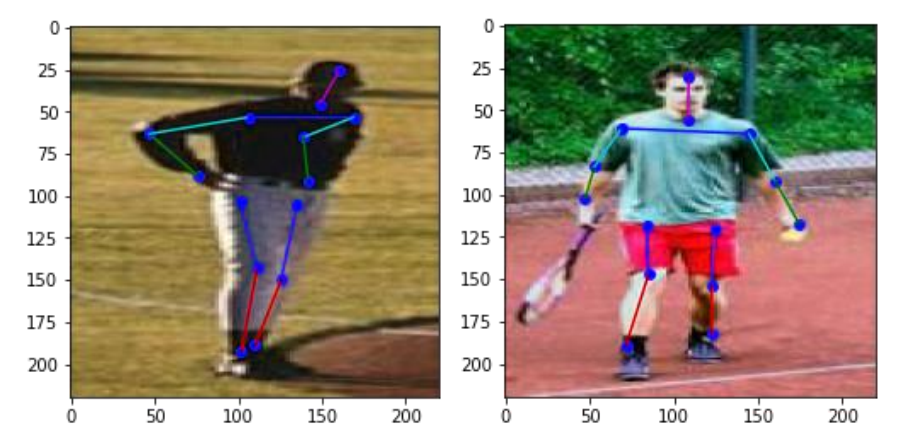
4.2 Test images